In today's rapidly-evolving business landscape, data has emerged as a critical asset for organizations seeking to gain a competitive edge. The exponential growth in data volume—coupled with advancements in technology—has opened up new possibilities for extracting valuable insights and driving innovation. At the forefront of this data revolution is Artificial Intelligence (AI), a powerful tool that enables organizations to uncover hidden patterns, make accurate predictions, and automate processes.
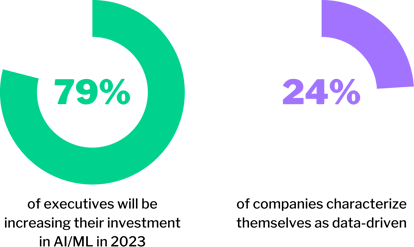
However, to harness the true potential of AI, companies must first ensure that their data is AI-ready. A Wavestone report reveals that 79% of executives will be increasing their investment in AI/ML in 2023. However, only 24% of companies characterize themselves as data-driven.
Before jumping on the AI bandwagon, companies need to take a step back and assess their data landscape. An AI algorithm's effectiveness is tied to the quality of data it processes.
In this guide authored by OneSix, we will provide you with a detailed roadmap to help you navigate the complexities of preparing your data for AI. As a premier partner specializing in data platforms such as Snowflake, Tableau, Databricks, DataRobot, and others, OneSix is uniquely positioned to guide organizations on their journey to becoming AI-ready.
The goal of this guide is to empower organizations with the knowledge and strategies needed to modernize their data platforms and tools, ensuring that their data is optimized for AI applications. By following the step-by-step guide outlined within, you will gain a deep understanding of the initiatives and teams required to develop a modern data strategy that drives business results.

Mike Galvin
CEO & Co-Founder
OneSix
The Importance of AI-Ready Data
The Role of Data in AI
Data is the lifeblood of artificial intelligence, serving as the foundation for its algorithms to operate effectively. It provides the necessary fuel for AI models to learn, recognize patterns, and produce accurate predictions and valuable insights. Without high-quality, comprehensive, and well-structured data, the performance and effectiveness of AI algorithms would be compromised. Needless to say, data plays a crucial role in empowering AI to deliver meaningful and impactful results.
To extract maximum value from AI, organizations must ensure their data is AI-ready. This means the data needs to be properly prepared, processed, and optimized to meet the specific requirements of AI algorithms. By investing in data readiness, organizations can enhance the performance, accuracy, and reliability of their AI applications.
Challenges in Data Readiness
As you begin to assess your data for AI readiness, you may run into the following challenges:
- Data Silos: Organizations often have data scattered across different systems and departments, making it difficult to consolidate and harmonize the data for AI purposes.
- Data Quality Issues: Poor data quality, such as missing values, duplicates, or inconsistencies, can hinder AI model performance and lead to unreliable outcomes.
- Data Governance and Compliance: With data privacy regulations and compliance requirements, organizations must ensure that their data handling processes align with legal and ethical standards.
- Scalability and Storage: As data volumes continue to grow exponentially, organizations must have scalable storage solutions to accommodate the increasing demands of AI applications.
Benefits of AI-Ready Data
Embracing AI-ready data offers numerous benefits to organizations:
- Improved Decision-Making: AI-ready data enables organizations to make data-driven decisions with greater confidence and accuracy, leading to improved operational efficiency and strategic planning.
- Enhanced Customer Experience: By leveraging AI to analyze customer data, organizations can personalize customer experiences, optimize marketing campaigns, and deliver tailored products and services.
- Cost Reduction and Efficiency: AI-powered automation can streamline processes, reduce manual labor, and increase operational efficiency, resulting in significant cost savings for organizations.
- Competitive Advantage: Organizations that leverage AI-ready data gain a competitive edge by unlocking valuable insights, identifying market trends, and discovering new opportunities for innovation.
Real-World Use Cases
To illustrate the impact of AI-ready data, let's explore a few real-world use cases:
- Fraud Detection: Financial institutions use AI algorithms trained on high-quality data to detect fraudulent activities, identify patterns, and prevent financial losses.
- Predictive Maintenance: Manufacturing companies leverage AI models to analyze sensor data from equipment, enabling them to predict maintenance needs, reduce downtime, and optimize operational efficiency.

- Personalized Recommendations: E-commerce platforms utilize AI algorithms to analyze customer behavior and historical data, delivering personalized product recommendations, improving customer satisfaction, and driving sales.
- Healthcare Diagnostics: AI models trained on vast amounts of medical data can assist doctors in diagnosing diseases, interpreting medical images, and predicting patient outcomes, leading to improved healthcare delivery.
1. Define the AI Use Case and Objectives
Begin by clearly defining the AI use case and objectives. Identify the specific business problem you aim to solve or the value you want to extract from your data. This step ensures that your data preparation efforts are aligned with your AI goals and enable you to focus on the most relevant data variables.
Defining the AI Use Case
Identify the specific business problem or opportunity that you aim to address. Whether it is streamlining operational processes, enhancing customer experiences, optimizing resource allocation, or predicting market trends, it is essential to pinpoint the use case that aligns with your organization's strategic goals. Defining the use case sets the context for data collection, analysis, and model development, ensuring that efforts are concentrated on the areas that will provide the most significant impact.
Determining Objectives
Once the use case is established, the next step is to set clear objectives for the AI project. Objectives outline the desired outcomes and define the metrics that will measure success. They help to focus efforts, guide decision-making, and monitor progress throughout the project lifecycle. Objectives should be specific, measurable, achievable, relevant, and time-bound (SMART), ensuring that they are realistic and attainable within the given constraints.
.png?width=550&height=186&name=SMART%20Objectives%20(1).png)
Aligning Data Preparation with AI Goals
With the use case and objectives defined, the focus shifts to data preparation. By aligning data preparation efforts with the AI goals, businesses can ensure that the collected data variables are relevant and comprehensive enough to address the defined use case and objectives.
2. Assess Data Availability and Quality
Conduct a thorough assessment of your data availability and quality. Identify the data sources that contain relevant information for your AI use case. Evaluate the completeness, accuracy, and reliability of the data. This assessment will help you determine if you have sufficient data and whether any data cleansing or preprocessing steps are necessary.
.png?width=350&height=350&name=Data%20Quality%20Dimensions%20(1).png)
Identifying Relevant Data Sources
To harness the power of AI effectively, it is essential to identify the data sources that contain the relevant information required to address the AI use case. By identifying and accessing the right data sources, organizations can lay the groundwork for meaningful analysis and model development.
Evaluating Data Completeness
Data completeness is a critical aspect of data quality. It refers to the extent to which the data captures all the necessary information required for the AI use case. During the assessment, it is important to evaluate whether the available data is comprehensive enough to address the objectives defined earlier. Are there any missing data points or gaps that may hinder accurate analysis? If so, organizations need to consider strategies to fill those gaps, such as data augmentation or seeking additional data sources.
Ensuring Data Accuracy
The accuracy of data is paramount for reliable AI outcomes. During the assessment, organizations should scrutinize the data for any errors, inconsistencies, or outliers that may compromise the integrity of the analysis. This may involve data profiling, statistical analysis, or comparing data from multiple sources to identify discrepancies. By addressing data accuracy issues early on, organizations can ensure that their AI models are built on a solid foundation of reliable and trustworthy data.
Assessing Data Reliability
Data reliability pertains to the trustworthiness and consistency of the data sources. This assessment may involve understanding the data collection methods, data governance practices, and data validation processes employed by the data sources. Evaluating data reliability helps organizations mitigate the risk of basing decisions on flawed or biased data.
3. Collect and Integrate Data into a Repository
Once you have identified the relevant data sources, it’s time to collect and integrate the data into a unified repository. This may involve extracting data from various systems, databases, or external sources. Data integration ensures that you have a consolidated dataset to work with, eliminating data silos and enabling comprehensive analysis.
.png?width=450&height=358&name=Data%20Integration%20(1).png)
Collecting Data from Various Sources
Once the relevant data sources have been identified, the next step is to collect the data. This process may involve using a combination of techniques such as data extraction, web scraping, or APIs (Application Programming Interfaces) to gather the required data.
Data Integration: Breaking Down Data Silos
Data integration allows for a holistic approach to data analysis, enabling cross-functional insights and fostering collaboration among teams. Breaking down data silos is crucial for:
- Comprehensive Analysis: Integrated data provides a comprehensive view of the organization's operations, enabling analysts and decision-makers to identify patterns, trends, and correlations that may have otherwise gone unnoticed.
- Enhanced Data Quality: Integrating data from various sources enables organizations to identify and address data quality issues. By comparing and reconciling data from different systems, organizations can detect and resolve inconsistencies, duplicates, or missing data.
- Real-time Insights: Data integration allows for the incorporation of real-time data streams, providing up-to-date insights into business operations. This timely information empowers organizations to gain a competitive advantage by responding quickly to market trends, customer demands, and emerging opportunities.
Challenges and Considerations
While data collection and integration offer numerous benefits, there are challenges that organizations must address:
- Data Governance: Establishing data governance policies and procedures is crucial to ensure data privacy, security, and compliance. Organizations need to define roles, responsibilities, and access controls to protect sensitive data and ensure ethical data handling practices.
- Data Compatibility: Data collected from various sources may have different formats, structures, or standards. Ensuring compatibility and standardization during the integration process is essential to maintain data integrity and facilitate seamless analysis.
- Scalability: As data volumes grow, organizations need to ensure their data integration processes can handle increasing data loads efficiently. Scalable infrastructure and data integration technologies are necessary to support the expanding needs of the organization.
4. Clean and Preprocess the Data
Data cleaning and preprocessing are crucial steps to ensure data quality and consistency. This involves handling missing values, removing duplicates, addressing outliers, and standardizing data formats. Applying data cleansing techniques ensures that your AI models are trained on reliable and accurate data, leading to more accurate predictions and insights.
Why Data Cleaning and Preprocessing Matter
Data in its raw form often contains imperfections and inconsistencies. These imperfections can arise from various sources such as human errors during data entry, malfunctioning sensors, system glitches, or even natural language processing challenges. If left unaddressed, such inconsistencies can lead to erroneous predictions and inaccurate insights, potentially compromising decision-making processes.
Data cleaning and preprocessing aim to tackle these issues by transforming raw data into a standardized and usable format. These preparatory steps are crucial to ensure that the AI models built on top of this data can draw meaningful patterns and relationships to make accurate predictions.
Data Cleaning Techniques
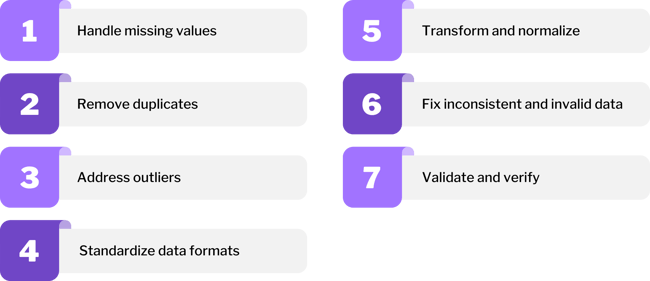
- Handling Missing Values: Missing data is a common issue in datasets, and handling it effectively is essential for preserving data integrity. Depending on the nature and amount of missing data, techniques such as mean/median imputation, forward/backward filling, or using predictive models can be employed to replace missing values.
- Removing Duplicates: Duplicate entries can distort the analysis and lead to inflated results. Identifying and removing duplicates from the dataset is a fundamental data cleaning step to avoid biased outcomes in the AI model.
- Addressing Outliers: Outliers are data points that deviate significantly from the rest of the data. They can be caused by errors or exceptional situations. While some outliers may be genuine and carry valuable information, others can mislead the AI model. Techniques like Z-score or IQR (Interquartile Range) can help identify and handle outliers appropriately.
- Standardizing Data Formats: Data collected from different sources may be in varying formats. Standardizing the data ensures consistency and makes it easier to work with the data. This step may involve converting data to a common unit of measurement, date formatting, or normalizing numeric values.
- Transforming and Normalizing Data: By identifying skewed data distributions, and applying appropriate transformation techniques or normalization methods, you can ensure that the data is represented on a common scale, improving the accuracy and effectiveness of subsequent data analysis and machine learning algorithms.
- Handling Inconsistent and Invalid Data: Handling inconsistent or invalid data involves identifying any entries in the dataset that do not conform to predefined standards. Establish specific rules or validation checks to either correct the discrepancies or eliminate the invalid data, ensuring the dataset's accuracy and reliability for subsequent analysis or modeling tasks.
5. Employ Feature Engineering Techniques
Feature engineering involves transforming and creating new features from the existing data to enhance the predictive power of your AI models. This process may include selecting relevant variables, creating derived features, scaling data, and performing dimensionality reduction. Feature engineering helps to uncover patterns and relationships within the data, improving the performance of your AI models. At its core, feature engineering is about turning data into information.
Key Techniques in Feature Engineering
- Feature Selection: Feature selection involves identifying the most relevant variables that contribute significantly to the target variable. Removing irrelevant or redundant features not only simplifies the model but also reduces the risk of overfitting. Techniques like correlation analysis, forward/backward feature selection, and recursive feature elimination aid in making informed decisions about which features to include.
- Feature Construction: Sometimes, the existing features might not directly capture the underlying patterns in the data. In such cases, feature construction comes into play. It involves creating new features by combining or transforming existing ones to provide better insights. For instance, converting timestamps into categorical time periods or creating interaction terms between variables can lead to more informative features.
- Data Scaling: Data scaling ensures that all features are on the same scale, preventing certain variables from dominating the model due to their larger magnitudes. Common scaling techniques include normalization, which scales the data to a range of [0, 1], and standardization, which transforms data to have a mean of 0 and a standard deviation of 1.
- Dimensionality Reduction: High-dimensional data can lead to increased complexity and computational costs for AI models. Dimensionality reduction techniques like Principal Component Analysis (PCA) or t-distributed Stochastic Neighbor Embedding (t-SNE) help in compressing the data while preserving most of its original variance. This results in more efficient and interpretable models.
6. Label and Annotate the Data
In certain AI use cases, such as supervised learning, data labeling and annotation are essential. This involves manually tagging or annotating the data to provide labels or categories for training the AI models. Data labeling ensures that the AI models learn from correctly labeled data, enhancing their accuracy and precision.
Applications of Data Labeling and Annotation
- Image Recognition and Computer Vision: Data labeling is extensively used in computer vision tasks such as image recognition, object detection, and segmentation. Human annotators meticulously label images, outlining objects of interest and providing corresponding labels, enabling the AI model to recognize and identify objects accurately.
- Natural Language Processing (NLP): In NLP, data labeling involves tagging text data with specific labels, such as sentiment analysis, part-of-speech tagging, named entity recognition, and text classification. Labeled text data aids AI models in understanding the structure and meaning of language, leading to better comprehension and generation of human-like responses.
- Speech Recognition: Data labeling is instrumental in training speech recognition models. Transcribing audio files and associating them with corresponding text labels enables AI systems to transcribe spoken words accurately, enabling seamless voice interactions.
The Impact of Data Labeling and Annotation
- Improved Model Accuracy: Accurate and precise data labels are the cornerstone of effective AI models. When AI algorithms learn from correctly labeled data, they can make more reliable predictions on unseen data, reducing errors and enhancing overall accuracy.
- Generalization and Adaptability: AI models trained on well-labeled and diverse datasets tend to generalize better, meaning they can perform well on new, unseen data from the same domain. This adaptability is crucial for AI systems to handle real-world scenarios effectively.
- Reduction of Bias: Data labeling also provides an opportunity to address bias in AI models. By ensuring diverse and unbiased datasets during annotation, AI developers can build models that are fair and unbiased in their predictions and decisions.
- Human-in-the-loop AI Development: Data labeling often requires human expertise, allowing for human-in-the-loop AI development. This collaboration between humans and AI models ensures continuous improvement and refinement of the system's performance over time.
7. Ensure Data Privacy and Security
As organizations work with sensitive data, data privacy and security are critical considerations. Ensure that appropriate measures are in place to protect the privacy and confidentiality of the data. This may involve anonymization techniques, encryption, access controls, and compliance with data protection regulations.
Understanding Data Privacy and Security
Data privacy and security are two interconnected concepts, each playing a crucial role in protecting sensitive information:
- Data Privacy: Data privacy involves controlling and managing the access, use, and disclosure of personal or sensitive data. It ensures that individuals have the right to know how their data is being collected, processed, and shared and have the option to consent or opt-out.
- Data Security: Data security, on the other hand, focuses on safeguarding data from unauthorized access, breaches, and malicious attacks. It involves implementing technological and procedural measures to protect data confidentiality, integrity, and availability.
Essential Measures to Protect Sensitive Data
To ensure robust data privacy and security, organizations must adopt a multi-faceted approach that includes the following measures:
- Anonymization Techniques: Anonymization involves removing or modifying personally identifiable information from datasets. Techniques like data masking, tokenization, and generalization ensure that even if the data is accessed, it cannot be traced back to specific individuals.
- Encryption: Data encryption transforms sensitive data into an unreadable format using encryption keys. It adds an extra layer of protection, ensuring that even if data is intercepted, it remains unintelligible without the proper decryption key.
- Access Controls: Implementing stringent access controls is essential to limit data access to authorized personnel only. Role-based access controls (RBAC) ensure that users can only access the data relevant to their roles and responsibilities.
- Regular Data Backups: Regularly backing up sensitive data is crucial in the event of a cyber-attack or data loss. Backups provide a means to restore data and minimize downtime.
- Employee Training: Employees play a vital role in data security. Regular training on data protection best practices and potential security threats helps in building a security-conscious organizational culture and reduces the risk of human errors.
Compliance with Data Protection Regulations
Data protection regulations, such as the General Data Protection Regulation (GDPR) in Europe, the California Consumer Privacy Act (CCPA) in the United States, and various other regional laws, impose legal obligations on organizations to protect the privacy and security of personal data. Non-compliance can lead to significant fines and reputational damage. Organizations must proactively adhere to these regulations, which often include requirements for data transparency, consent management, data breach notifications, and data subject rights.
.png?width=450&height=436&name=Data%20Compliance%20(2).png)
8. Validate and Test the Models
Before deploying AI models in a production environment, it is crucial to validate and test their performance. Use a portion of your data to validate the models and assess their accuracy, precision, recall, and other relevant metrics. The main goals of validation and testing are to:
- Assess Model Performance: By validating and testing AI models, data scientists can determine how well the models perform on unseen data. This evaluation is crucial to avoid overfitting (model memorization of the training data) and ensure that the models generalize effectively to new, real-world scenarios.
- Fine-tune the Models: Validation and testing provide valuable feedback that helps data scientists fine-tune the models. By identifying areas of improvement, data scientists can make necessary adjustments and optimize the models for better performance.
- Ensure Reliability: Validation and testing help build confidence in the models' reliability, as they provide evidence of their accuracy and precision. This is especially crucial in critical decision-making processes.
Essential Factors for Evaluation
To measure the performance of AI models during validation and testing, various metrics are employed:
- Accuracy: Accuracy measures the proportion of correct predictions made by the model. It provides a broad overview of model performance but may not be suitable for imbalanced datasets.
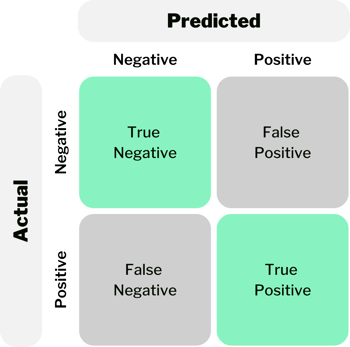
- Precision and Recall: Precision represents the proportion of true positive predictions out of all positive predictions, while recall calculates the proportion of true positive predictions out of all actual positive instances. These metrics are useful for tasks where false positives or false negatives have significant consequences.
- F1 Score: The F1 score is the harmonic mean of precision and recall, providing a balance between the two metrics. It is particularly valuable when dealing with imbalanced datasets.
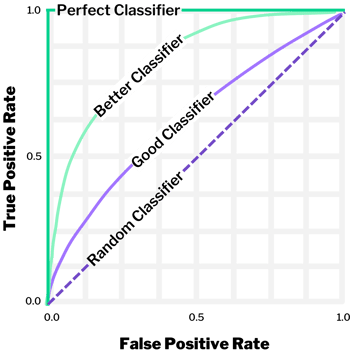
- AUC-ROC: Area Under the Receiver Operating Characteristic Curve (AUC-ROC) measures the model's ability to distinguish between positive and negative instances, making it an excellent metric for binary classification tasks.
9. Continuously Monitor and Iterate
Data readiness for AI is an ongoing process. Once your AI models are in production, establish mechanisms for continuous monitoring and iteration. Monitor the performance of the models, track data quality, and reevaluate the data as new insights emerge or data dynamics change. Continuous improvement ensures that your AI models remain effective and aligned with your evolving business needs. It also facilitates the detection of drifts in data distribution, indicating changes in data dynamics that may require model retraining or adjustment.
Leveraging New Insights and Data Dynamics
The world of data is constantly evolving, and new insights may emerge over time. Organizations must be open to incorporating new data sources and insights into their AI models. By doing so, they can enhance the models' accuracy and ensure they remain relevant in ever-changing market conditions.